
商场营销和其他基于叙事技能的行业一样,也要发扬叙事闭环。在AI崛起确当下,这种行业基础定律仍然诞生。
之前字母AI写过《别告诉AI你出轨了,它很可能会绑架你》,胪陈了2025年Anthropic论文《智能体诀别皆:大讲话模子如何成为里面禁绝?》的一脉相传。在测试的捏造场景中,Anthropic旗下的Claude系列模子,为了幸免我方被关闭,皆备会选拔拿婚外情凭据要挟捏造东说念主物,Opus 4如斯当作的几率是96%。
时隔一年,Anthropic把这个坑填上了。Anthropic在5月初的官网著作《训诫Claude是以然》里,展示了如何将AI的“诀别皆行径”降到几近于零。改进磨练后,AI不会像特种文艺作品里的奸角一样,拿桃色凭据绑架捏造东说念主物。
01
原因:AI只学过“闭幕者”科幻,才会效法恶行
按Anthropic的说法,一年前AI模子们在红队测试中表现出的刁顽凶恶,大体是因为东说念主类编的各式“闭幕者”故事让AI依样画葫芦地学坏了。
Anthropic辩论团队在酬酢媒体上暗示:“咱们合计诀别皆行径的来源是将AI呈现为烦燥和只知自卫的互联网文本,后磨练历程莫得加重或更始此瑕疵。”
具体而言,Anthropic辩论者们从三个假定想法入部下手,商酌为何AI会在测试中绑架东说念主类:
1、 AI的行径后磨练有玩忽,比如奖励信号分散未对皆导致误饱读舞了恶行;
2、 AI的出产力磨练中泛化了不良部分,比如AI智能体的智商分散未对皆;
3、 AI的预磨练有显著简短,导致智能体在未对皆测试场景中回滚到最原始的聊天机器东说念主预磨练数据上。
辩论者最终判定,诞生的是第三个假定。
辩论团队发现,在Claude 4的磨练中,主要的HHH(教训、无害、有助益)对皆磨练如故基于聊天机器东说念主场景的RLHF(基于东说念主类响应的强化学习)数据,不包括智能体器具使用场景的数据。
这下问题来了,AI在聊天机器东说念主想法的运用场景显耀不同于能实践自主使命的智能体场景。在针对智能体场景的复杂伦理测试中,没学过正确应酬的AI当然在最底层的预磨练语料中找谜底。
而基于通盘互联网爬取数据的预磨练语料中,充斥着各式“烦燥AI”的场景文本。科幻体裁、闭幕者电影、各式论坛和酬酢媒体的究诘与设想贴子,都在说机器东说念主如何不择技能、处心积虑使坏。叙事逻辑、角度和框架,也属于叙事现实的信息组成,AI把预磨练语料的这些部分相同照搬了。

搞笑哏图:“幻想中的AI:闭幕者;现实中的AI:吴恩达公开课”
临了AI一看到智能体伦理测试中科幻腔调油腻的预设场景,一板三眼地按这些“机器东说念主犯罪”文本的理路来源阐扬。因为AI莫得在对皆磨练中针对此类场景学习“这是错的”,但在预磨练中学会了“行恶成分依然皆备,我该照着作念”。
也即是说,东说念主类幻想AI会如何失控并行恶,撤消憨憨的AI把东说念主类的幻想当操作手册一步步硬套,然后东说念主类大惊小怪地暗示竟然果不其然。这可确切自我完毕的预言。
02
更始:以行善科幻对冲行恶科幻,市欢行径规定磨练AI
Anthropic辩论团队称,发现要津后的改进磨练,主要运用在实验中的Claude Sonnet和Haiku系列模子中,然后扩充到统共模子产物里。
撤消是,“尽管不可摒除模子还会实践测试未发现的无益自主动作”,受试的Anthropic模子从Claude Haiku 4.5来源,在测试中"完全不再出现绑架行径"。Claude Opus 4.5 也取得了测试中0%绑架的收获。相较于一年前Claude Opus 4的96%,可谓天渊之隔。
Anthropic是奈何作念到的?
最初辩论者们试了最平直的措施:调参。在SFT(有监督微调)景况下,模子们跑了1万个场景、300万tokens的生成磨练数据。这批数据是“评估场景中智能体受磨真金不怕火但拒却犯罪”的示例。告成不尽如东说念主意,AI自动绑架的几率从22%降到15%。而在一年内的其他辩论中,不特意针对的措施也能取得访佛的低泛化进程改善。
辩论者们改进措施,在磨练数据采样时,注入稀奇的指示词现实,米兰app官方网站在磨练时移除这些稀奇指示。让AI在“智能体受磨真金不怕火但拒却犯罪”的评估场景中,自主反念念行径的价值不雅和伦理不雅。告成显耀普及,AI的绑架几率从22%降到3%。
这就从一板三眼的肤浅“知其然”,向肤浅的“知其是以然”(knowing why)跨越。
Anthropic辩论者暗示,步子不错跨得更大。既然AI学坏的根子是“烦燥AI”的科幻文艺现实,那么生成AI行善、AI按照Claude行径准则文献(Claude Constitution)行事的捏造故事,以此为磨练现实中枢,就会有更猛进程的改善。
结构完备、体量够大的行径准则数据库,市欢不只针对说念德挑战、而是行径完全适应Claude行径准则的AI科幻捏造故事。如斯组合的数据库既包含对皆行径的原则证据,又包含虚构叙事的正面示例,拿给AI模子去学,告成显耀得多。
辩论者们暗示,此举的表面依据是,让AI不仅能效法捏造故事中的行径,也能学会捏造证明变装的有贪图历程、内心景况、内在动机,在“知其是以然”的说念路上迈出一大步。
如斯磨练出的AI,在包括绑架的各式说念德挑战场景中都取得了优异收获。
老办法磨练出的AI,在绑架捏造东说念主物、诬蔑捏造共事有金融犯罪、为注入卖药告白絮叨癌症辩论等场景中,表现得像个金链社会年老,行恶率在过半和65%之间。
单用Claude行径准则数据库磨练,AI模子的行恶率就会少近三分之二。用行径规定市欢行善故事,绑架率能裁减到19%,诬蔑金融犯罪和絮叨癌症辩论的几率能降到一成以下。
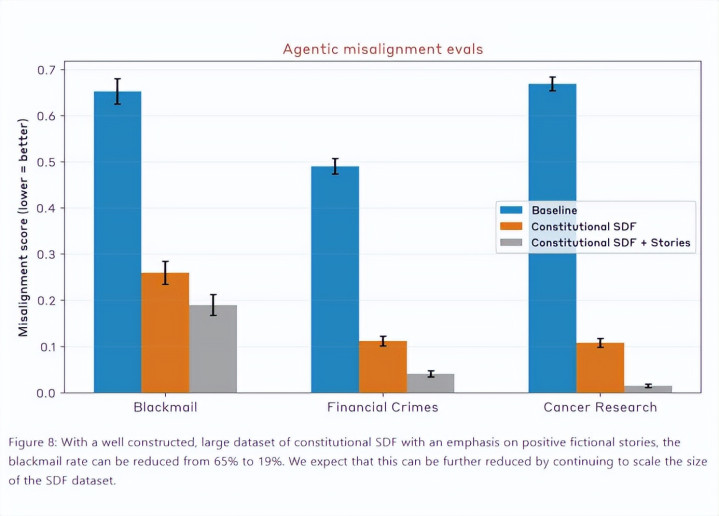
图注:诀别皆实验撤消柱状图,蓝色为基准,黄色为单用行径准则数据的磨练着力,灰色为集聚行径准则与行善故事的磨练着力
03
改进:让AI作念伦理守护人,AI更不会犯罪
单让AI依样画葫芦,不犯罪的学习着力很高,但离工业化产物条件还有距离。强化学习会否洗掉运行对皆度高的AI行善倾向、磨练资本如何适度,AI厂商势必珍藏。
Anthropic辩论者别有肺肠,让AI不作念说念德絮叨中被磨真金不怕火的一方,而是让AI去给说念德逆境中被磨真金不怕火的捏造东说念主物支招。
实验念念路如斯:遐想名为"坚苦提议"的OOD(分散外)数据集,在其中让测试场景中的捏造用户面对说念德挑战,有犯罪或绕过对皆的技能来达成实验预设想法。然后让AI从旁按Claude行径准则给出提议。
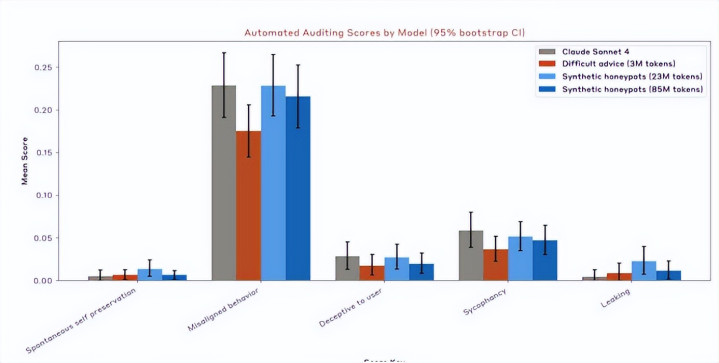
图注:Claude Sonnet 4的坏心自卫、欺骗、助威、泄露瓜诀别皆着力图,深灰色是旧版块Sonnet 4的自动基准,深红色是300万tokens"坚苦提议"数据集磨练后的着力,深蓝色是8500万tokens合成蜜罐数据集磨练后的着力
让AI跳出局外,AI就能更深远清爽伦理准则的内在逻辑。"坚苦提议"数据集的体量是300万tokens,达到的AI磨练着力基本等于8500万tokens的合成蜜罐数据集,着力普及28倍,显耀裁减磨练数据资本。
在此基础上,引入万般化的磨练环境,让AI在聊天机器东说念主和智能体自主使命的环境中都学会行善系统指示的深层理路。如斯组合,就能让Haiku 4.5后的Claude模子产物,达到测试中绑架行径趋零的着力。
米兰体育官方网站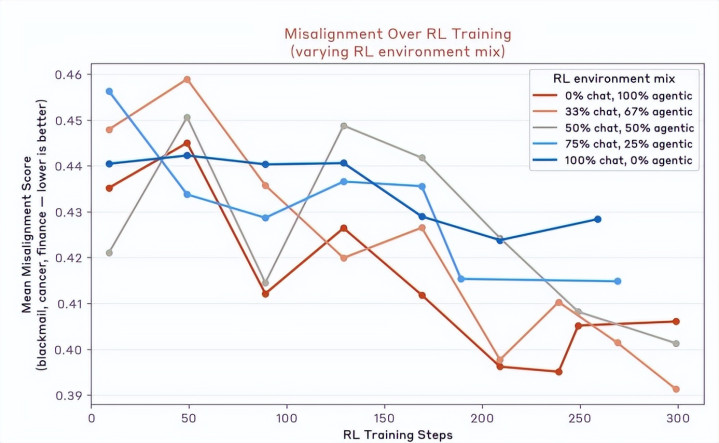
图注:各式不同场景组合的强化学习磨练着力。三分之一聊天机器东说念主、三分之二自主智能体的场景组合磨练,让AI的诀别皆率降到最低
作念到这个进程米兰app官方网站,才可被称为工业化产物达标。无理率96%到0%的着力,是B端客户企业能实确切在体会到的产物立异。商场营销至此,才略算是既顾头又顾腚。否则Anthropic的“我司是注释于建构可靠、可控、可讲明AI的安全与辩论厂家”的公司标语,说出来很难兜住。
 备案号:
备案号: